
With the rise of AI-generated code flooding development pipelines, many enterprise developers face the challenge of maintaining code quality amid rapid automation. Can Anthropic's new Code Review tool embedded in Claude Code actually lighten this burden? This article examines how this multi-agent system works and its real-world implications.
What is Anthropic's Code Review Tool and How Does It Work?
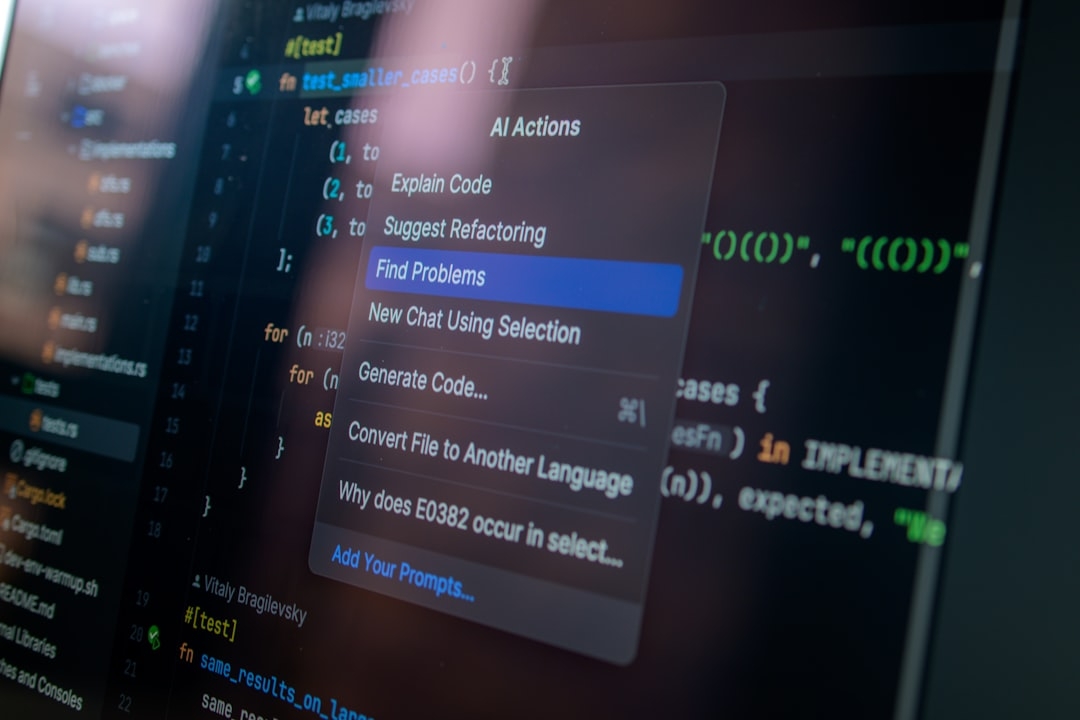
Anthropic's Code Review is integrated within Claude Code, an AI platform designed to handle multi-agent collaboration in coding tasks. The core function of this tool is to automatically analyze AI-generated code and flag logic errors before it reaches human developers. In simple terms, it reads through the code much like a senior programmer checking for mistakes or flawed reasoning.
This approach is crucial because AI models often generate syntactically correct code that subtly contains logical bugs—errors that compilers or basic linters don't catch. By introducing automated logic review, Anthropic aims to reduce the time developers spend hunting for these issues, which helps especially in enterprise settings where volumes of AI-generated code are soaring.
Why Is Managing AI-Generated Code Challenging for Enterprises?
AI-generated code is growing exponentially, making manual review impractical. Traditional code review processes rely heavily on human attention to detail, but with AI producing vast amounts of code, the bottleneck shifts from writing to validating that code's correctness.
Many organizations face two major issues:
- Quality Assurance: AI can produce errors in logic, security flaws, or inefficient algorithms that humans must identify and correct.
- Scalability: Teams can't scale human review fast enough to keep pace with AI code output, leading to delays or overlooked issues.
Anthropic’s tool tries to address these by automating a layer of review that focuses on catching logical problems, not just syntax or styling.
How Does Anthropic’s Solution Compare to Traditional Code Review?
Traditional code reviews are manual and time-consuming, involving peer reviews and testing phases that can delay software delivery. AI-assisted code generation accelerates development, but it raises quality concerns.
Anthropic’s system acts as a middle ground: it’s not fully replacing human reviewers but automatically filtering out obvious errors that would waste human time. Its multi-agent design means multiple AI agents collaborate to cross-check code, enhancing error detection capabilities.
However, the tool’s trustworthiness depends on the reliability of its error detection algorithms. In production environments, false positives or missed errors can create bottlenecks or risks.
When Should Enterprises Use Anthropic's Code Review Tool?
Enterprises should consider deploying this tool when:
- They face a high volume of AI-generated code requiring quick validation.
- Development teams want to reduce manual review overhead without compromising too much on quality.
- They are experimenting with integrated AI toolchains and need a system that can coordinate multiple AI agents for enhanced quality checks.
Conversely, in highly sensitive applications where errors can have critical consequences, human oversight remains indispensable. Automated code review tools like Anthropic’s should be viewed as complementary rather than absolute safeguards.
What Are the Trade-Offs and Limitations?
While Anthropic’s automated review system offers clear benefits, some trade-offs include:
- Possible false positives that may slow down developers or lead to distrust in the tool.
- Coverage gaps: The system primarily focuses on logical errors, potentially missing deeper architectural or security issues.
- Dependency risks: Over-reliance on AI for code validation could cause complacency among developers.
Real-world implementation has shown that no automated tool fully replaces expert judgment. The success depends on striking the right balance between automation and human insight.
Quick Reference: Key Takeaways
- Code Review by Anthropic automatically analyzes AI-created code for logic errors.
- This tool helps enterprises manage growing volumes of AI-generated code.
- It reduces manual review workload but doesn’t eliminate the need for human oversight.
- Best suited for scaling review processes in lower-risk environments.
- Beware of false positives and gaps in error detection scope.
How to Decide if Anthropic's Code Review Fits Your Needs?
Determine the volume of AI-generated code in your workflow and establish the risk tolerance for undetected errors. Evaluate your current review team's capacity and how much automation can relieve their workload without causing new issues. Consider running pilot projects to measure the tool’s effectiveness compared to manual reviews.
Integrating Anthropic’s multi-agent system can be beneficial but requires cautious adoption and continuous monitoring to ensure quality standards.
Concrete Steps for Next Action
To decide on deploying an AI-driven code review tool like Anthropic’s, complete this checklist in about 15-25 minutes:
- Assess current volume of AI-generated code and review capacity.
- Identify critical code segments where errors have high impact.
- List existing pain points in manual review processes.
- Define acceptable error and false positive rates for automation.
- Plan a controlled pilot to compare tool outputs with human reviews.
This practical evaluation will help align expectations and decide if Anthropic’s Code Review enhances your development workflow or introduces new risks.
Technical Terms
Glossary terms mentioned in this article












Comments
Be the first to comment
Be the first to comment
Your opinions are valuable to us